Basic walk-through of an Extracted Features 2.0 file
- edkoehl
- Jennifer Christie
- Ryan Dubnicek
Learn what is inside an EF file, how the data is structured, and what it looks like.
In this guide:
Opening an Extracted Features file
Extracted Features 2.0 files are in JSON-LD format.
JSON is a structured data format that is written in key-value pairs or arrays (i.e., lists). For example, type:”Book” or date:1974.
“LD” stands for linked data, which means that data in the files can be interlinked to other data sources via Uniform Resource Identifiers (URIs), often in the form of Uniform Resource Locators (URLs, a kind of web link that you will find at various points in the file). Certain terms in the file are presented with a URI that links the entity to an ontology or vocabulary like Schema.org, or to authorities databases such as Virtual International Authority File (VIAF) or Library of Congress linked data resources. When no entry was found in a 3rd-party database, an entity was created for the name in a named entity database maintained by HTRC.
HTRC Extracted Features files are meant for a machine to read, not a human. An unformatted JSON file will look like one long string of data, which isn’t very helpful for human parsing of a file, piece by piece, as we will do here. There are two useful ways to make your JSON file “pretty”:
- A text editor, such as Oxygen XML
- Firefox web browser
If using a text editor, there is often a way to automatically format your JSON file that is more appealing to the human eye. In Oxygen, for instance, there is a button located on the top menu ribbon called “Format and Indent”:

After opening your file in Oxygen, you may click on this button and it will update the viewing format:
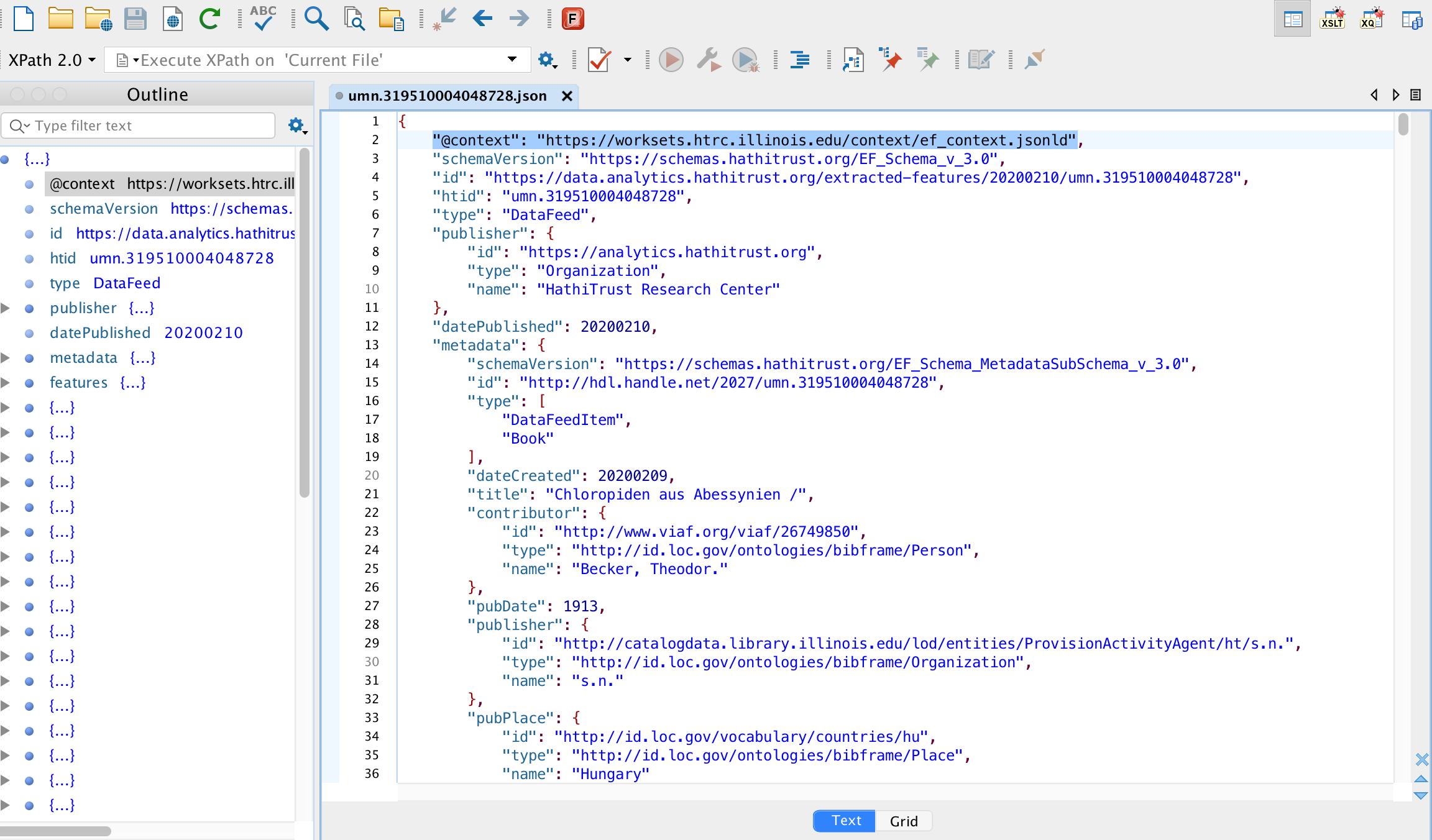
Firefox will automatically format JSON files for easy human readability. Simply open your Firefox browser, click File on the menu ribbon, and then select “Open File”. The file will appear in your browser window:
This documentation will continue to use Firefox as its viewing apparatus for image examples, due to its easy access and affordability (free).
When you first open a JSON file in Firefox, the terms and nodes will be collapsed:

You can click on the side panel arrow icons to expand the contents of each term/node/node object. (See first image above.)
This is what one Extracted Features file will look like when first opened in Firefox.
You’ll notice that as you expand any of these nodes, by clicking on the left side arrows, more information about the file is revealed. You can expand and minimize by clicking the arrows.
File description section
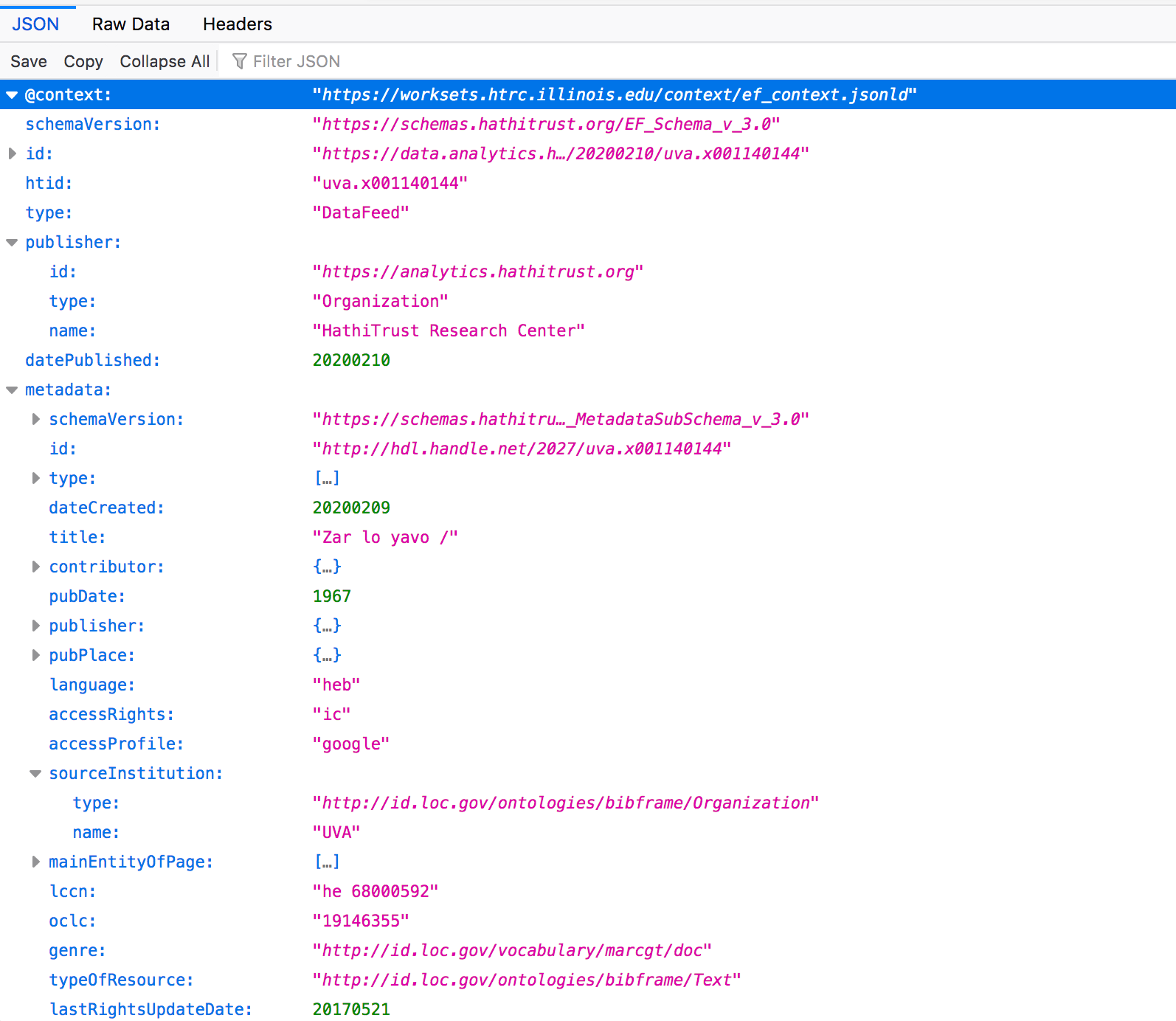
Each Extracted Features file opens with metadata describing the file itself.
If you expand the “context” data (click the arrow beside the term), the full URI is revealed:
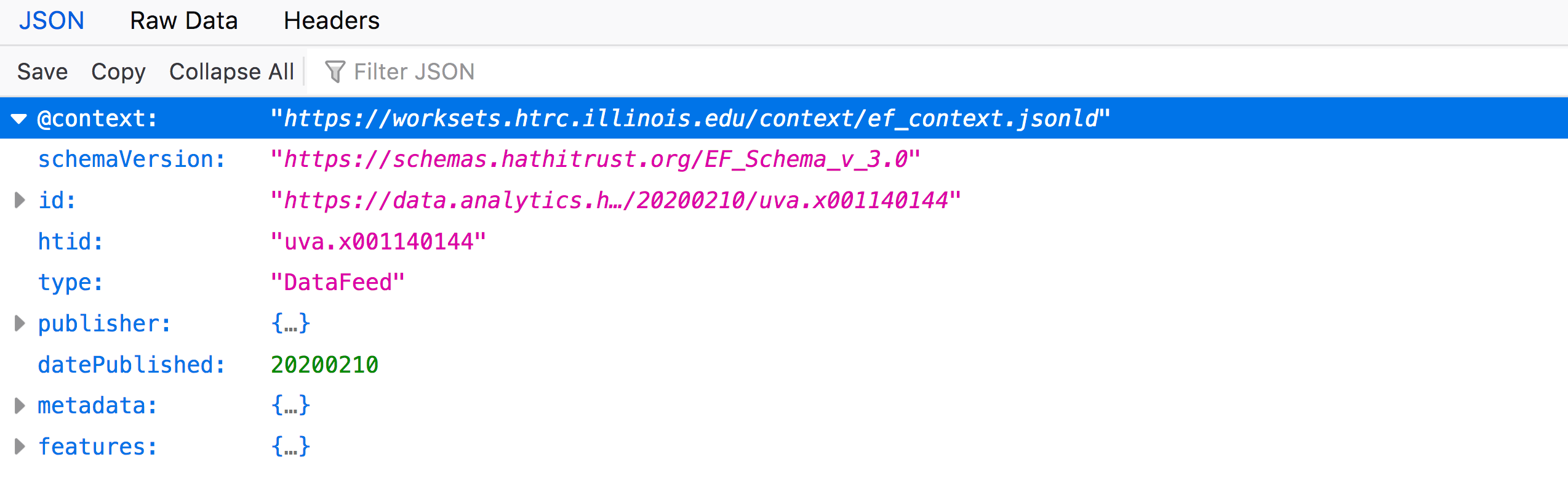
You won’t need to know what every single term means in order to use these files, but familiarizing yourself with the various objects within a file is helpful in understanding what “extracted features” are and how you might want to use them in your research.
For a full breakdown of all the EF JSON-LD terms, please refer to the 2.0 documentation here.
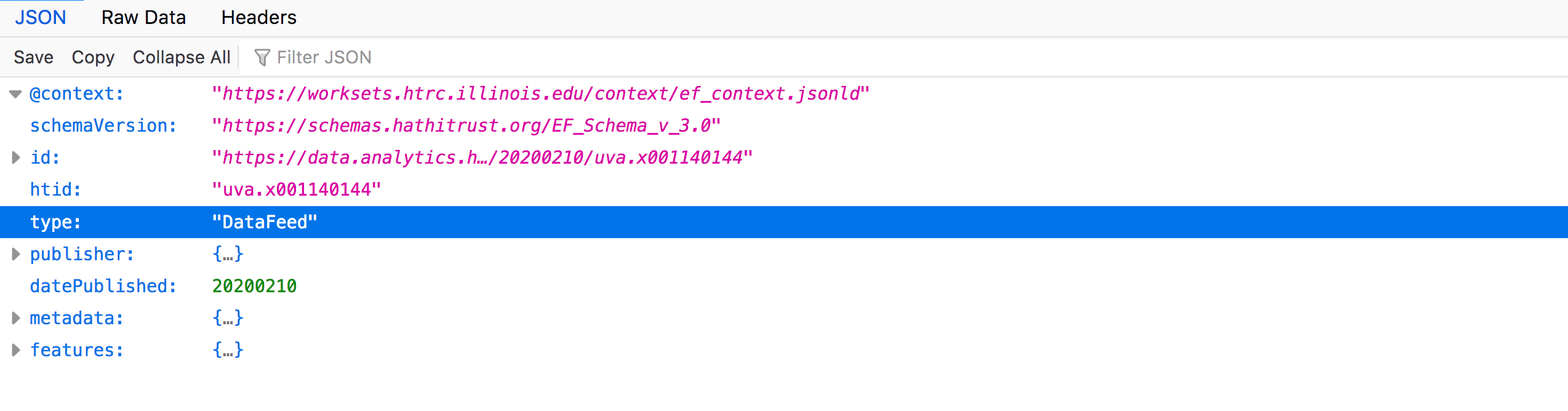
The first few terms in the JSON file relate to the EF file itself (i.e., “context”, “schemaVersion”, “htid”). “htid”, for example, is signifying that “uva.x001140144” is the HathiTrust volume ID for the item in HathiTrust to which this EF file refers.
You might assume that “publisher” and “datePublished” in this section of the file refer to the entity responsible for publishing the library volume (like a traditional publishing house), or when that volume was published, but these introductory terms are still referring to this EF JSON file itself. Therefore, when you expand “publisher”, you get the “id”, “type”, and “name” values associated with the HathiTrust Research Center (the creator of this individual file). These values are associated with that organization.
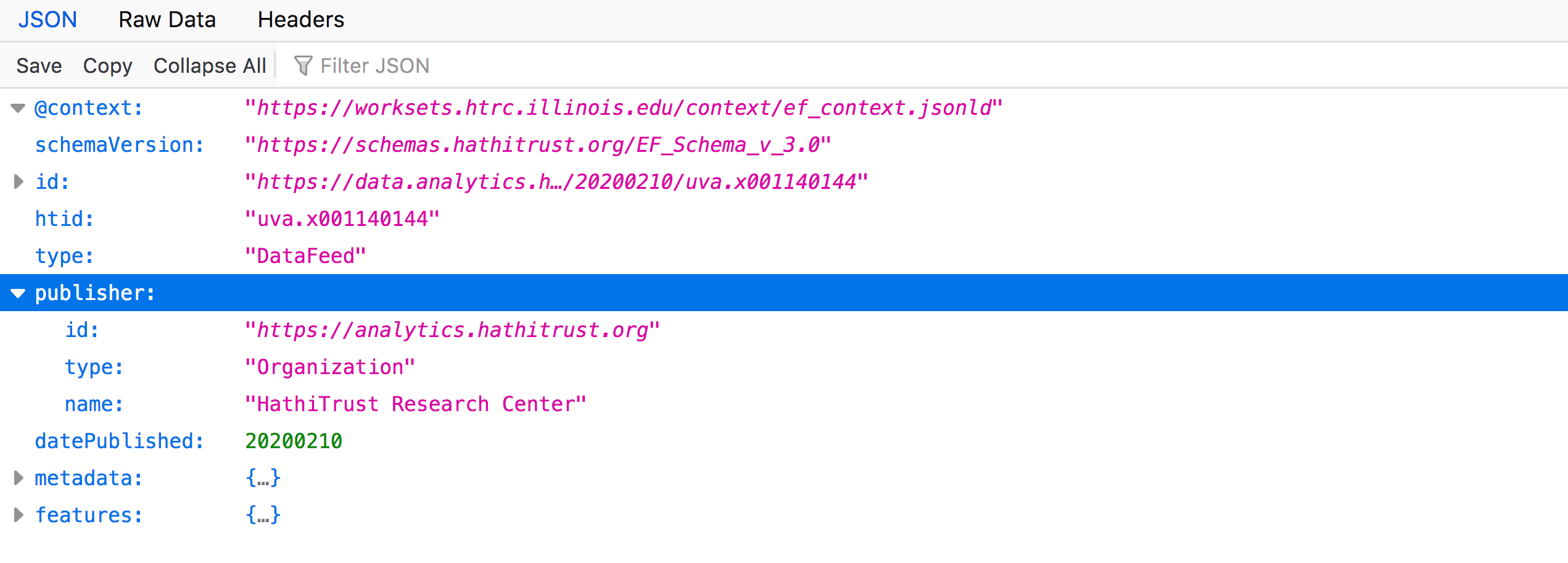
Metadata section
If you minimize the “publisher” node and expand the “metadata” node, you’ll see something like this:
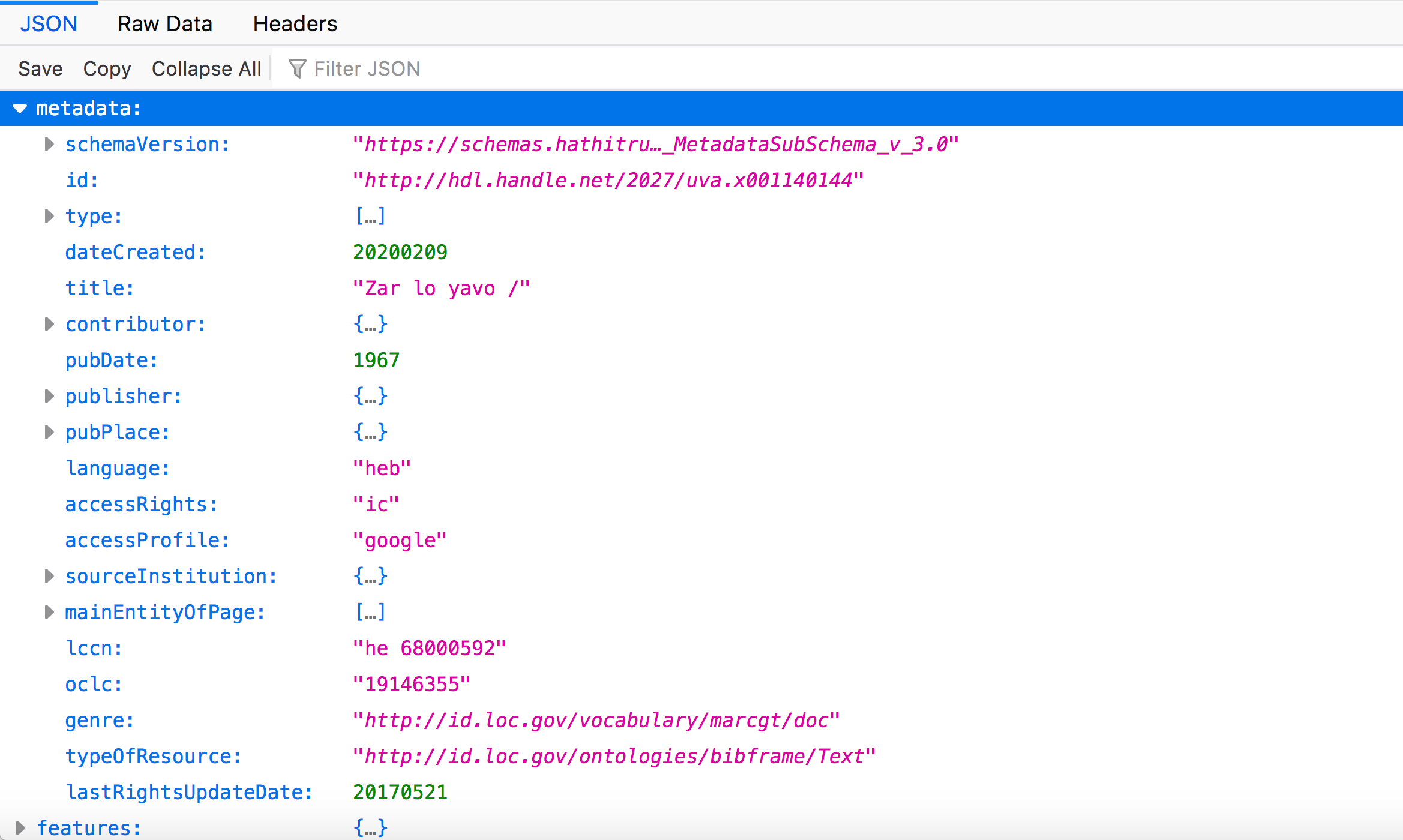
Some of these terms look familiar to those listed at the top of the file, such as “schemaVersion”, “id”, “type”, and “dateCreated”. Some of these terms are still associated with this specific file ("schemaVersion" and "dateCreated"), but now others refer to the volume itself ("id" and "type"). (Again, refer to this doc here if you want to know the full extent of these terms’ meanings and what their values indicate.)
More on ‘Metadata’
The metadata node object holds further nodes; the values of these nodes and their terms relate to information that describes the bibliographic entity that this EF file is generated from. In other words, this section of the file contains metadata about the volume itself. For instance, the “pubDate” value is “1967”, the year that this volume was originally published, and the “title” of this volume is “Zar lo yavo”.
There is more information in the metadata section, and you can expand and minimize to explore and see the full range of bibliographic metadata captured by the EF file.
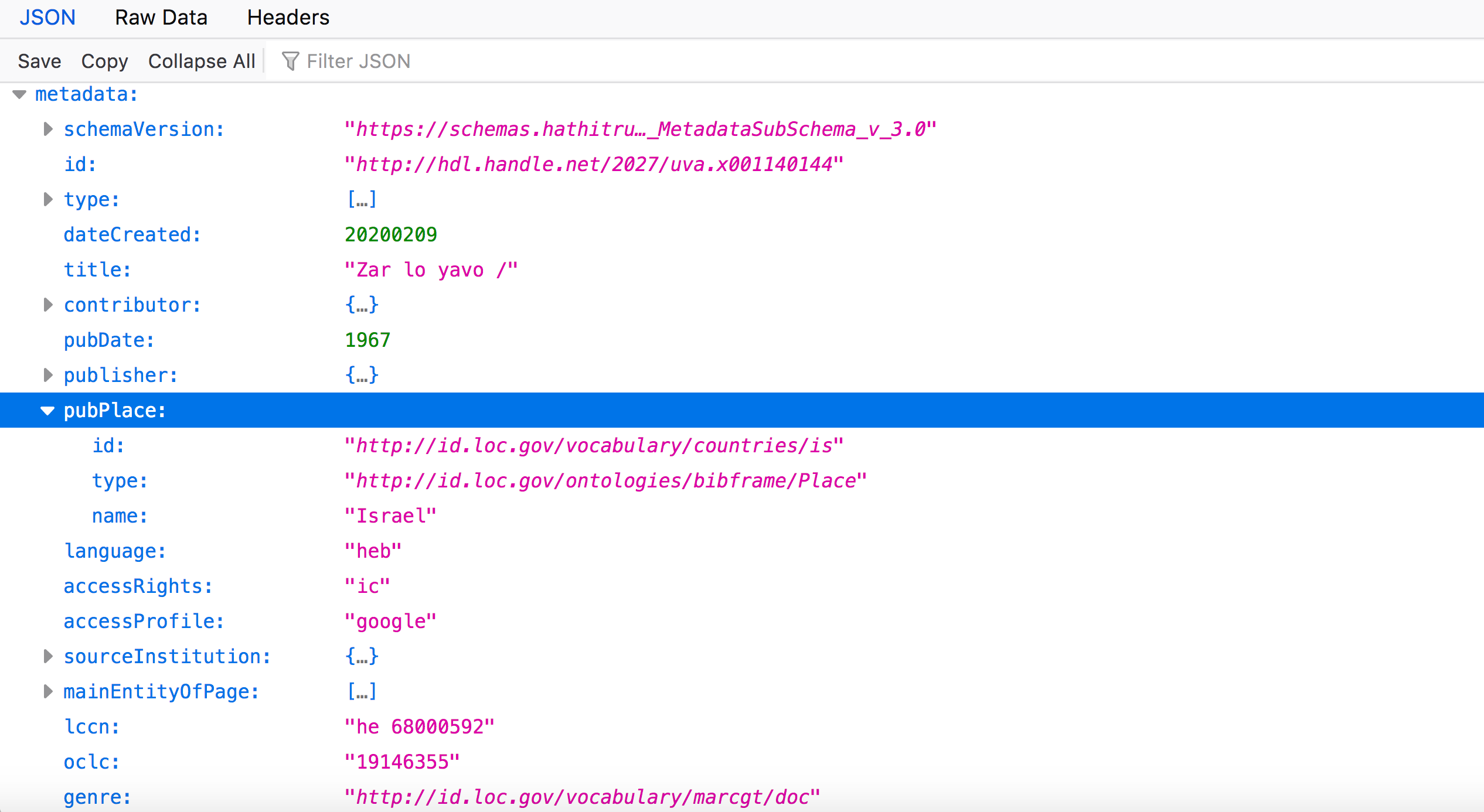
For example, you have the node object "pubPlace". "pubPlace" indicates information related to where the bibliographic entity was first (or originally) published. If you expand "pubPlace", there are additional nodes nested underneath that hold attributes of "pubPlace": here a "name" of the pubPlace, "Israel", information about the metadata field (here under "type") and a URI stored in "id" that links to an authority file for the place, the URI for "Israel" from the Library of Congress Linked Data Service.
We also see more nodes under "metadata" that may be of interest, including "language" and "accessRights". The "language" node object will tell you what language the volume was published in using MARC language codes (“heb”, or Hebrew, in this case), while "accessRights" holds information on if the volume is protected by copyright or in the public domain (indicated here with the value "ic", which stands for “in copyright”).
Features section
Minimize the "metadata" node and expand the "features" node. You’ll see something like this:
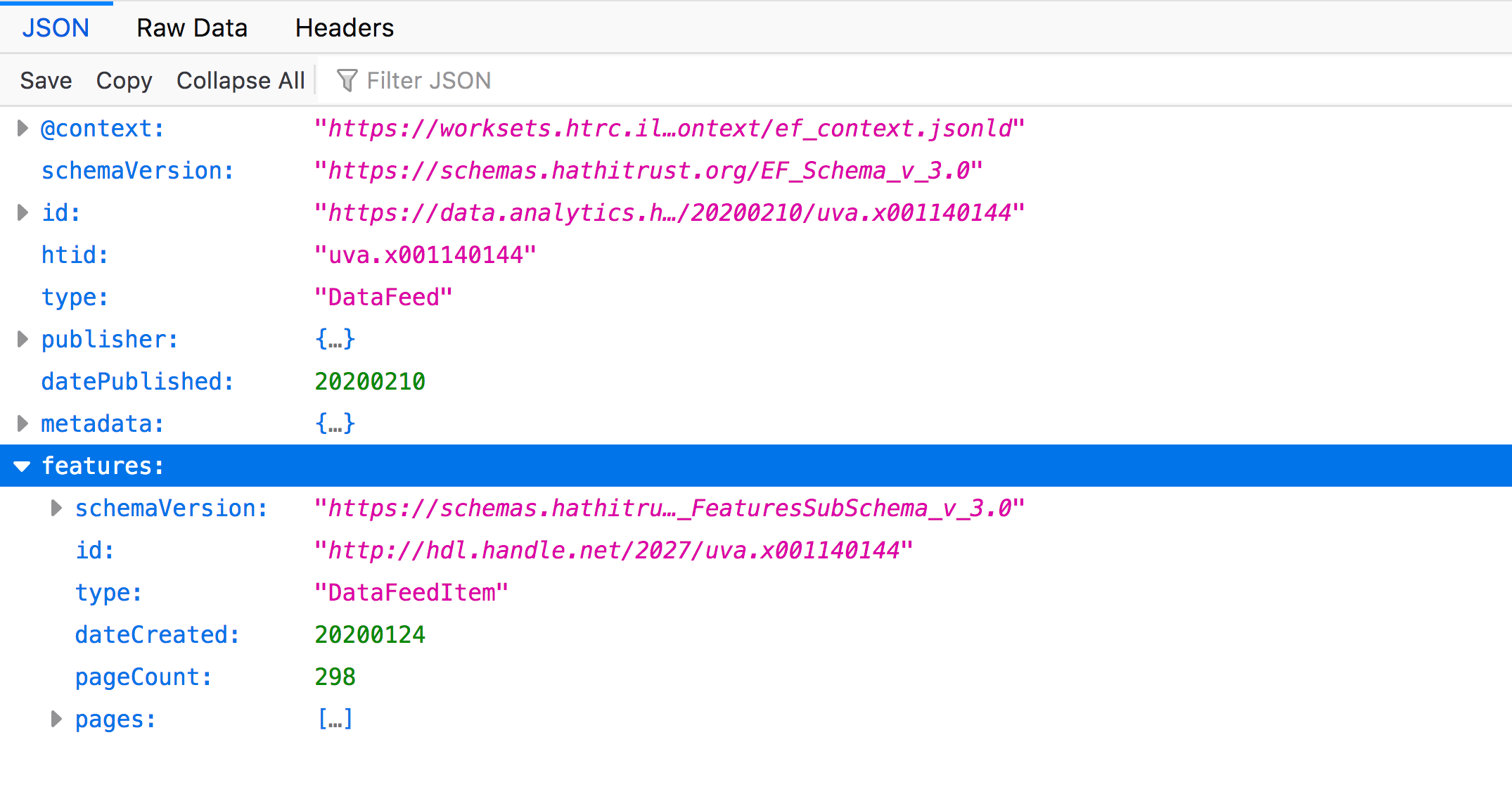
Once again, you will see some introductory terms like “id”, “type”, and “dateCreated”. You will also see "pageCount" which indicates the number of pages in the volume (here 298). Note the "pages" node and expand it.
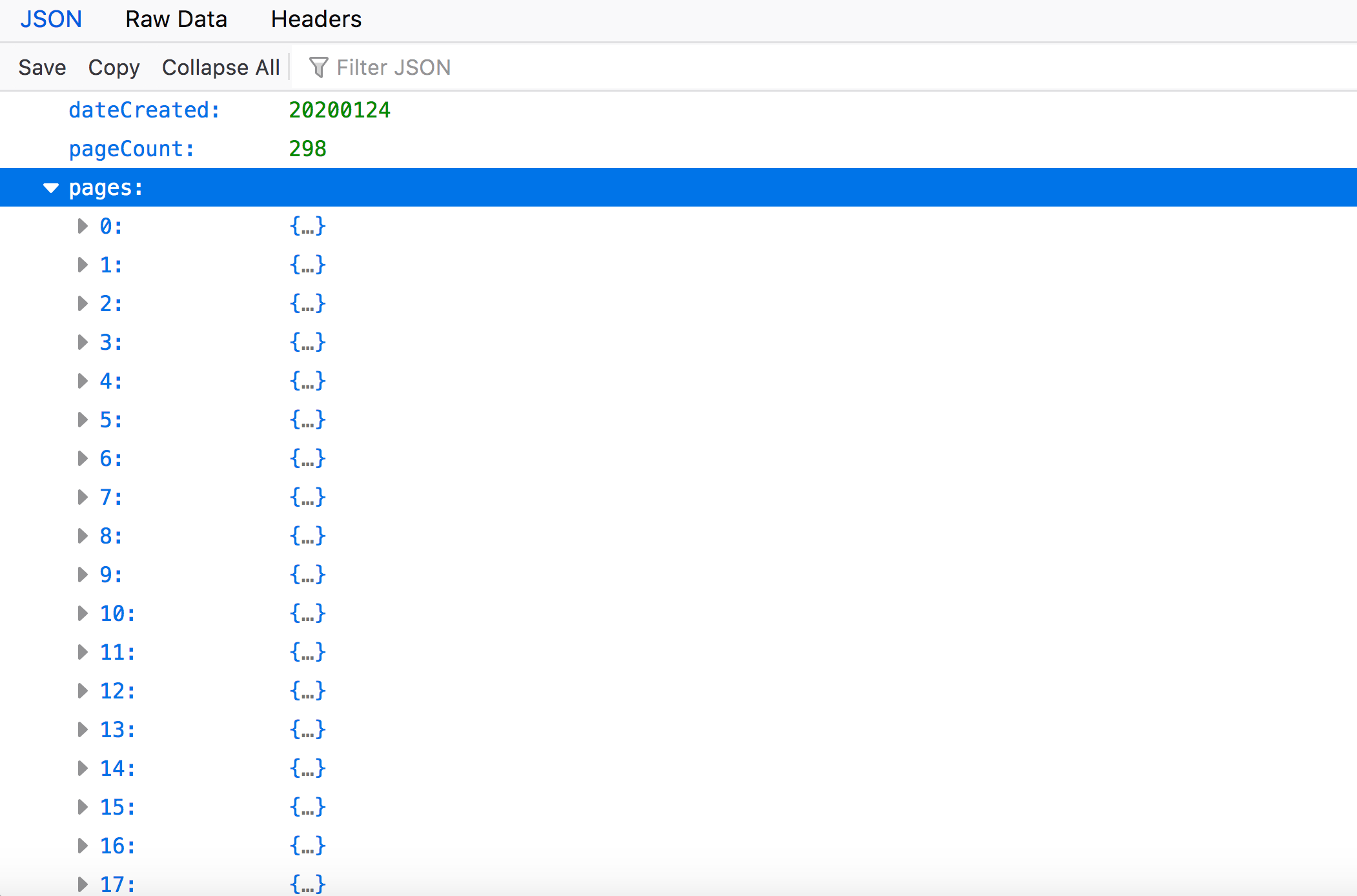
This is the section of the EF file that indicates the volume’s page-level extracted features metadata. Each page is represented as an individual node object in sequential order (i.e., in this case from page "0" through page "298"). Expand one of the page nodes.
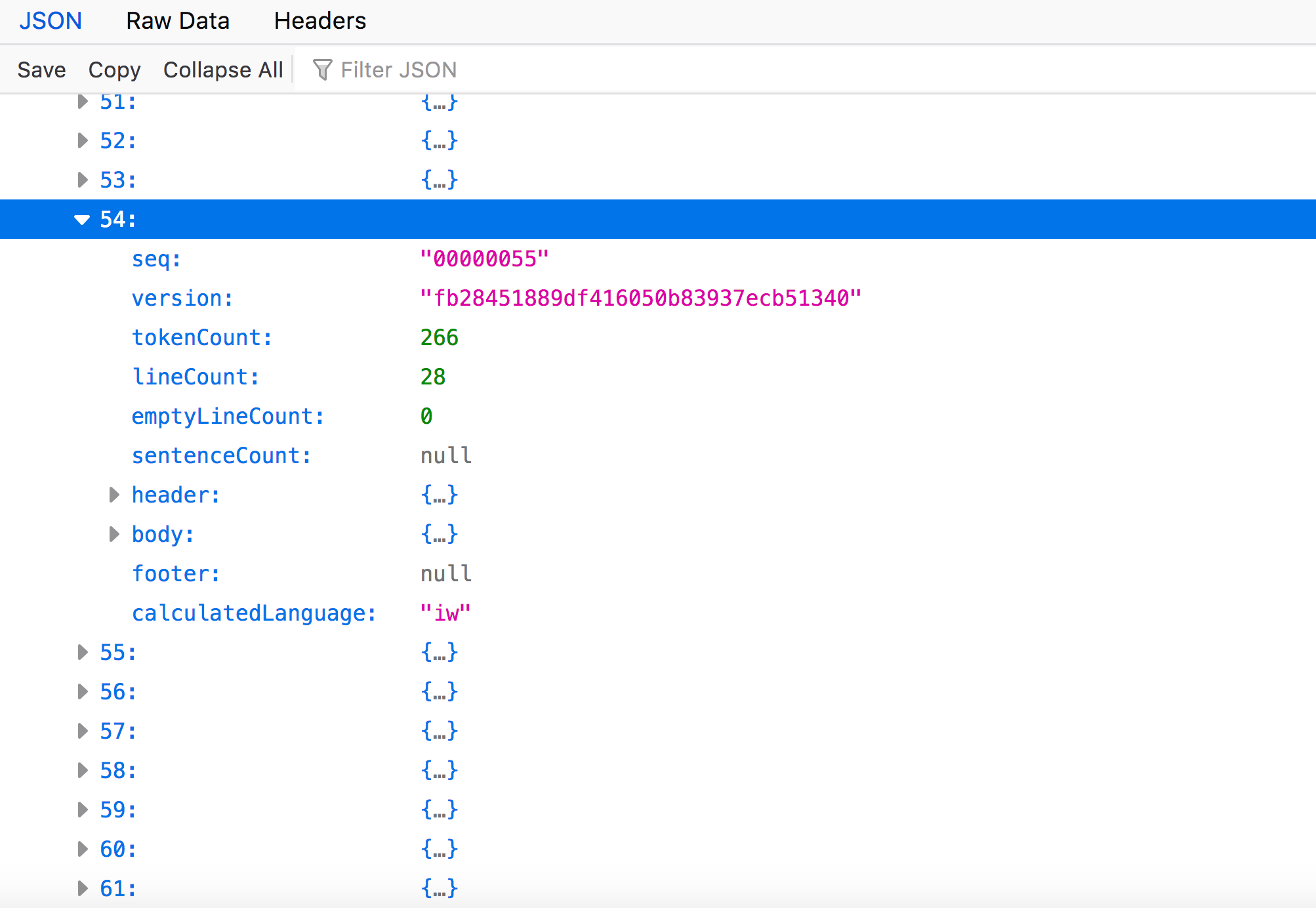
Here we can see “seq”, “version”, “tokenCount”, “lineCount”, “emptyLineCount”, and “calculatedLanguage”. We can also expand “header” and “body” information.
“Seq” and its value tell us a number that indicates a volume’s page position relative to the other pages in the volume. You’ll notice that the value is 55, not 54. That is because JSON begins arrays at 0, not 1. This is information that relates to page 55 of the volume.
“Version” is an MD-5 Hash that identifies the version of the page we are looking at.
“tokenCount” tells us how many words (a.k.a. tokens) are on this particular page. Similarly, “lineCount” signifies how many lines are on this page, and “empyLineCount” how many empty lines. Therefore, page 55 contains 266 words over 28 lines, which is a full page in this volume.
We can also see that the “calculatedLanguage” for this page is Hebrew (the value “iw” is the ISO 2 Letter Language Code used for Hebrew).
As you can see, there are even more nodes to expand within this page node, such as “header” and “body”. The “header” node object contains extracted feature metadata about content found within the header of the page (text that is separated from the body of the page). Likewise, “body” contains information about text located in the body.
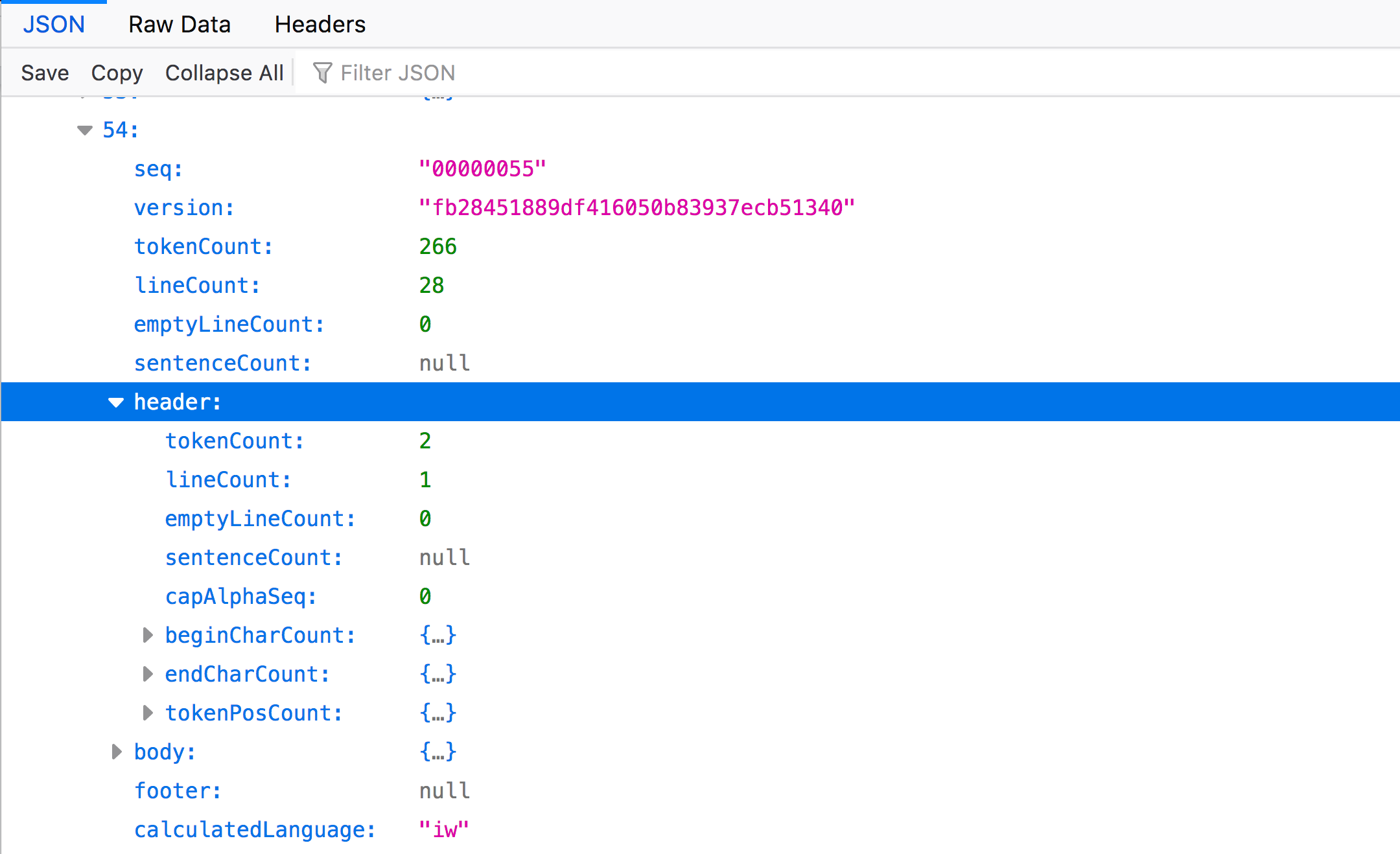
This header contains 2 tokens (“tokenCount’) in 1 line ("lineCount"). There are even more nodes to expand here, but we will move on to "body".
Once the body node is expanded, note that similar information as that listed in “header” is also displayed here, such as “tokenCount”, “lineCount”, “beginCharCount”, “endCharCount”, etc.
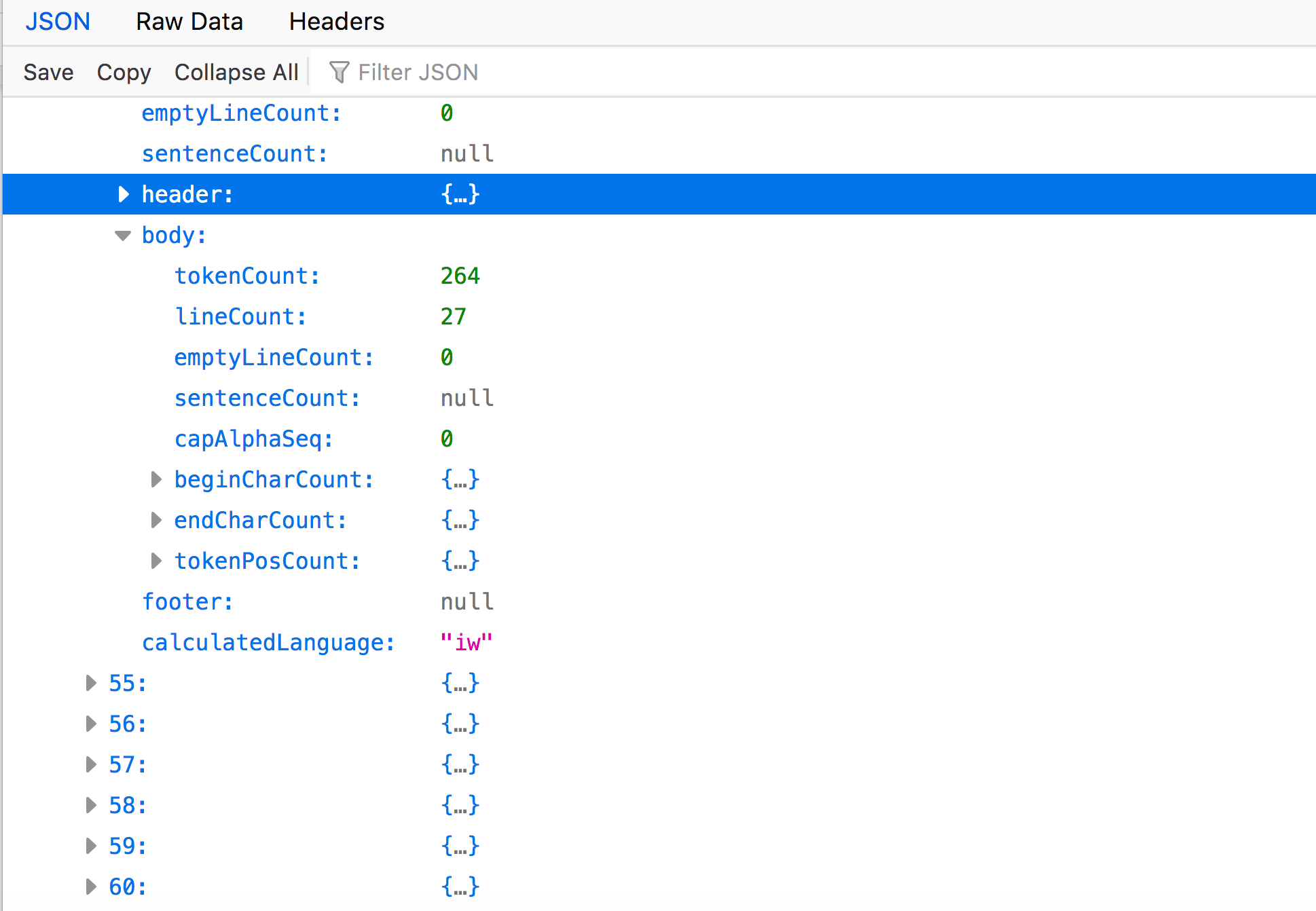
Expand “beginCharCount”:
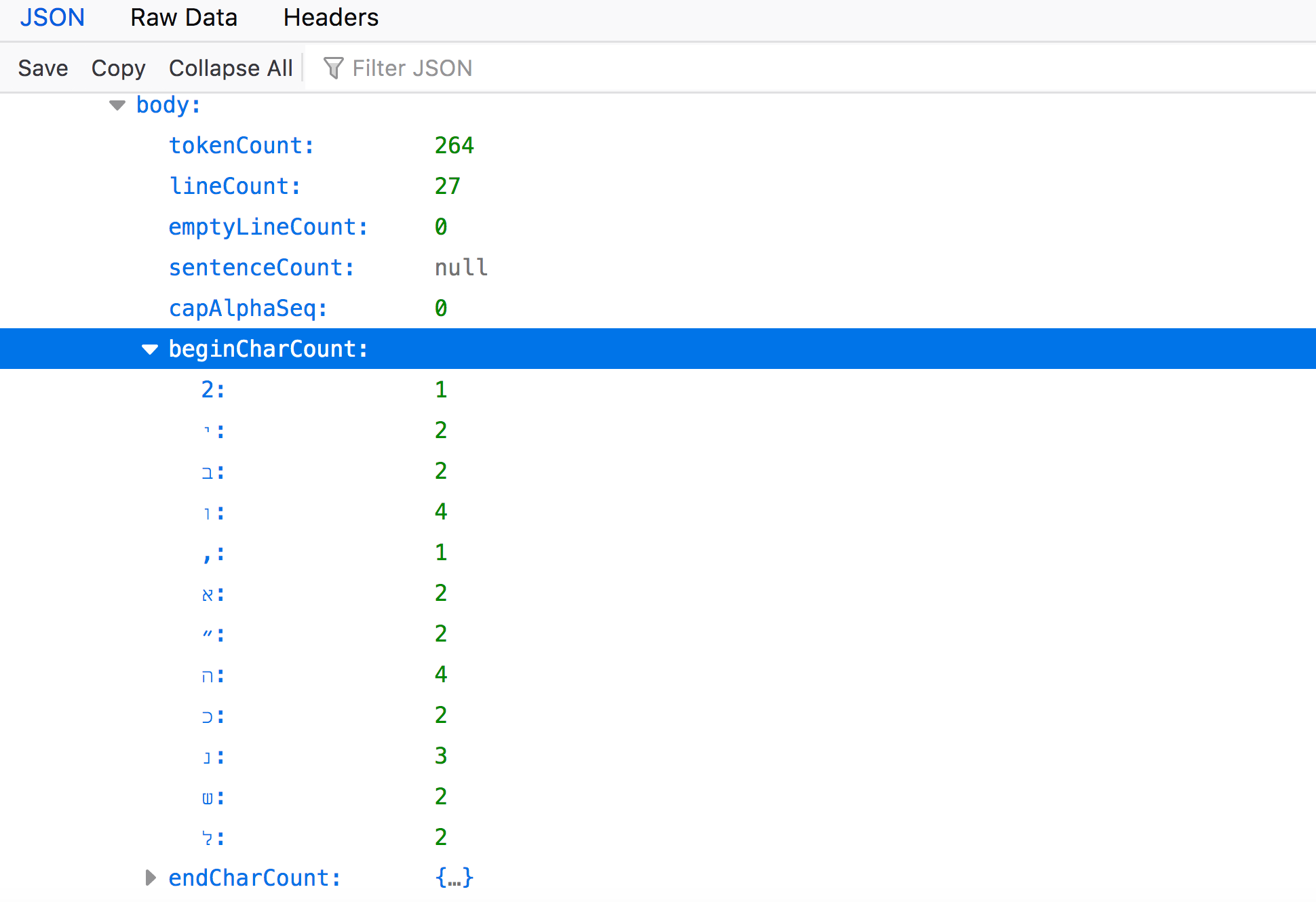
This section of the EF file is indicating all the characters that begin a line of text in the body of the volume. (Note: the number indicates how many times this character appears in this beginning position on the page. Also, because this volume is in Hebrew, these are characters from that language.)
If you collapse this node object and expand “endCharCount”, you’ll see that similar information has been extracted. “tokenPOSCount”, however, is by far the largest array. Expand the section to see.
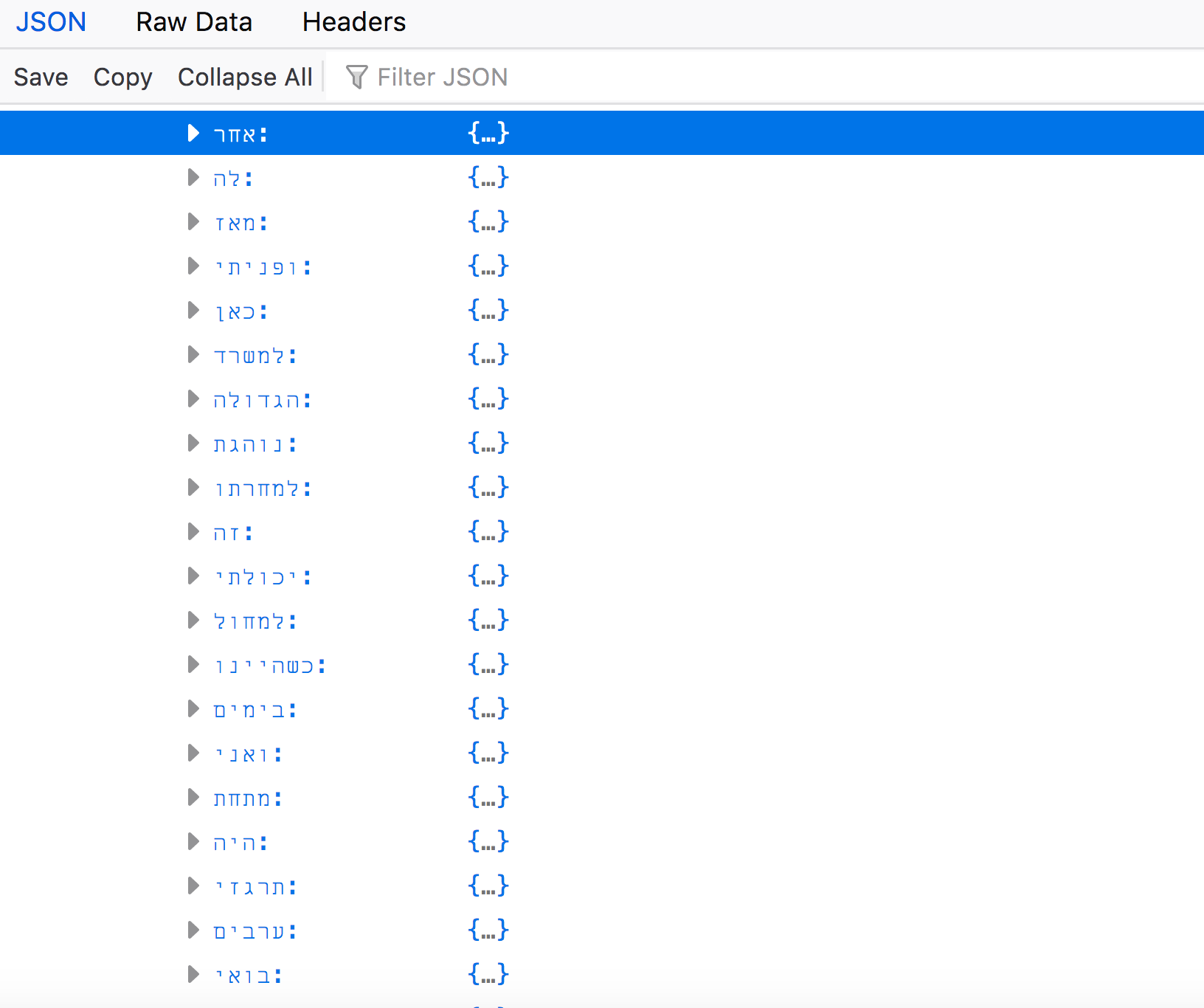
“tokenPOSCount” displays all the tokens (words) used on this page in the body, and the parts of speech they account for, with a number representing the number of times that token appeared in the. Note: The token will be listed as an expandable node -- once expanded you will see a part-of-speech tag indicating what part of speech the token is. For English, the tokens are tagged using codes from the Penn Treebank. For instance, NNP for a proper singular noun, or VBN for a past participle verb.
This is just a small portion of the parts-of-speech array. If you were to expand each node object, you would find the calculated POS tag signifying what kind of word the token represents grammatically.
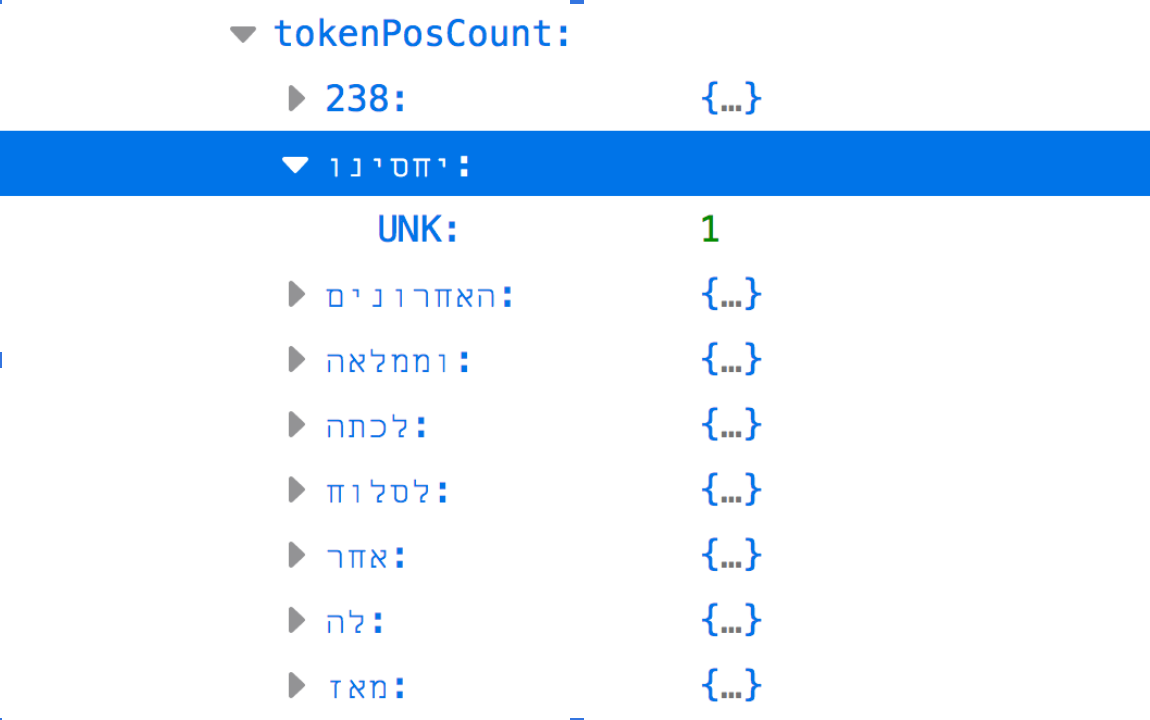
The token above is tagged as “UNK” which stands for “Unknown”, because the software used to create this part of the Extracted Features 2.0 files, Stanford NLP, does not support part-of-speech tagging for Hebrew. This token appears only one time in the body of this volume’s page.
If you were to move through each page of the document, you would find the tokens that appeared on that page, the part-of-speech if it could be determined, and the number of times it appeared on the page.
This is an introduction to the major features related to the Extracted Features file structure. This is not a comprehensive list of each term used in an EF JSON file. To read about each term used across the spectrum of EF volumes, please see this reference document.
This guide prepared by Jenny Christie