...
| Table of Contents | ||
|---|---|---|
|
Overview
The Extracted Features functionality (currently under beta release) is one of the ways in which users of HTRC's tools can perform non-consumptive analysis of texts in the HathiTrust Digital Library's corpus. This article explains how you can use the HTRC's workset functionality to download the EF files for a personalized collection. Currently, this functionality is available only for the HathiTrust Digital Library's public domain corpus, consisting of slightly less than 5 million volumes.
Sample file
The HTRC Extracted Features files are formatted in JSON. For more information about the fields, see the documentation for each release.
| Code Block | ||||
|---|---|---|---|---|
| ||||
{ "id":"loc.ark:/13960/t1fj34w02",
"metadata":{
"schemaVersion":"1.2",
"dateCreated":"2015-02-12T13:30",
"title":"Shakespeare's Romeo and Juliet,",
"pubDate":"1920",
"language":"eng",
"htBibUrl":"http://catalog.hathitrust.org/api/volumes/full/htid/loc.ark:/13960/t1fj34w02.json",
"handleUrl":"http://hdl.handle.net/2027/loc.ark:/13960/t1fj34w02",
"oclc":"",
"imprint":"Scott Foresman and company, [c1920]"
},
"features":{
"schemaVersion":"2.0",
"dateCreated":"2015-02-20T11:31",
"pageCount":230,
"pages":[
{"seq":"00000015",
“tokenCount":212,
"lineCount":38,
"emptyLineCount":10,
"sentenceCount":7,
"languages":[{"en":"1.00"}],
"header":{
"tokenCount":7,
"lineCount":3,
"emptyLineCount":1,
"sentenceCount":1,
"tokenPosCount":{
"I.":{"NN":1},
"THE":{"DT":1},
"INTRODUCTION":{"NN":1},
"DRAMA":{"NNPS":1},
"SHAKESPEARE":{"NNP":1},
"ENGLISH":{"NNP":1},
"AND":{"CC":1}}},
"body":{
"tokenCount":205,
"lineCount":35,
"emptyLineCount":9,
"sentenceCount":6,
"tokenPosCount":{
"striking":{"JJ":1},
"his":{"PRP$":1},
"plays":{"NNS":1},
"London":{"NNP":1},
"four":{"CD":1},
".":{".":7},
"dramatic":{"JJ":2},
"1576":{"CD":1},
"stands":{"VBZ":1},
...
"growth":{"NN":1}
}
},
"footer":{
"tokenCount":0,
"lineCount":0,
"emptyLineCount":0,
"sentenceCount":0,
"tokenPosCount":{}}}]}} |
Converting ID to RSync URL (Python with HTRC Feature Reader library)
The filepath to sync Extracted Features files through RSync follows a pairtree format, keeping the institutional shortcode intact (e.g. mpd, uc2).
If you are the HTRC Feature Reader library, there is a convenience function in htrc_features.utils.id_to_rsync(htid):
| Code Block | ||
|---|---|---|
| ||
>> from htrc_features import utils
>> utils.id_to_rsync('miun.adx6300.0001.001')
'miun/pairtree_root/ad/x6/30/0,/00/01/,0/01/adx6300,0001,001/miun.adx6300,0001,001.json.bz2' |
Converting ID to RSync URL (Python)
This example is a simplified part of a longer notebook, which further describes how to collect and download large lists of volumes: ID to EF Rsync Link.ipynb.
If you don't have it, you may have to install the pairtree library with: pip install pairtree (Python 2.x only).
| Code Block | ||
|---|---|---|
| ||
import os
from pairtree import id2path, id_encode
def id_to_rsync(htid):
'''
Take an HTRC id and convert it to an Rsync location for syncing Extracted Features
'''
libid, volid = htid.split('.', 1)
volid_clean = id_encode(volid)
filename = '.'.join([libid, volid_clean, kind, 'json.bz2'])
path = '/'.join([kind, libid, 'pairtree_root', id2path(volid).replace('\\', '/'), volid_clean, filename])
return path |
Example:
| Code Block | ||
|---|---|---|
| ||
id_to_rsync('miun.adx6300.0001.001')
'miun/pairtree_root/ad/x6/30/0,/00/01/,0/01/adx6300,0001,001/miun.adx6300,0001,001.json.bz2' |
The Extracted Features for this volume can be downloaded using RSync:
| Code Block | ||
|---|---|---|
| ||
rsync -azv data.analytics.hathitrust.org::pd-features/{{URL}} . |
If you have not yet created a workset, the Portal & Workset Builder Tutorial for v3.0 includes information on creating an account and building a Workset.
Generate and execute the data file transfer script
Go to the Algorithms page of the HTRC Portal
While logged into the HTRC Portal with the account you created your workset with, click on the 'Algorithms' link near the top of the screen.
...
From the list of algorithms that shows up, click on EF_Rsync_Script_Generator. This 'algorithm' generates a script for downloading the feature data files that correspond to your workset.

Execute the EF_Rsync_Script_Generator algorithm
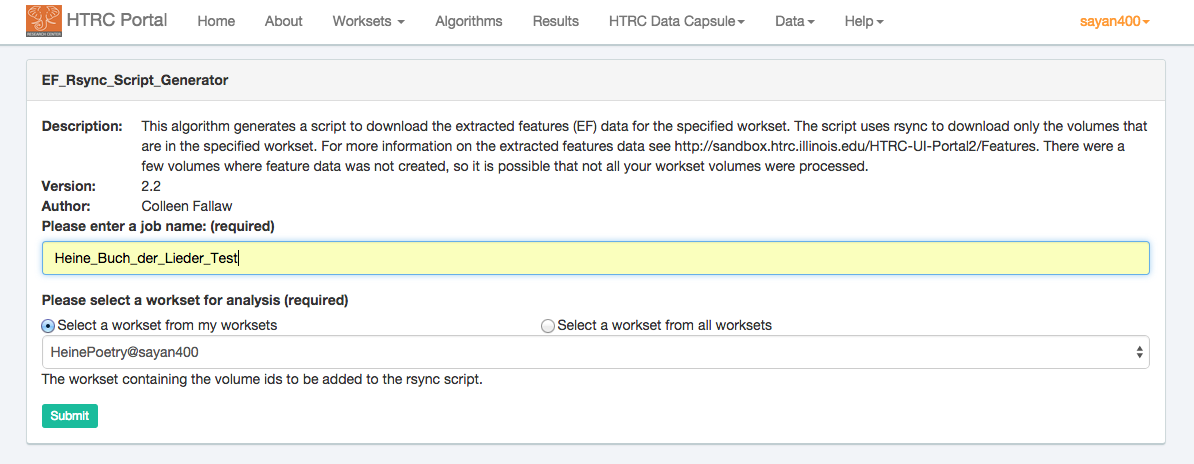
Specify a job name of your choosing. You also have to select a workset that the EF_Rsync_Script_Generator algorithm will run against: Check the button saying “Select a workset from my worksets” and select your desired workset. Your screen should now look like the figure below. At this point, click the ‘Submit’ button.
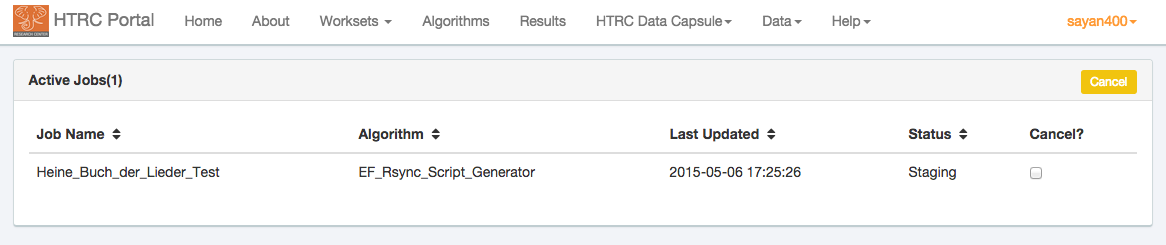
Check the status of the EF_Rsync_Script_Generator algorithm's execution
You can now see the status of the job, as shown below. The status of the job will initially show as “Staging”. (Refresh the screen after some time and you will see the status has changed to “Queued”. )
Open the completed job
Eventually, the job will have “completed”, and the screen, on refreshing, will look as follows. Click on the link representing the job name.

Download the results returned by the EF_Rsync_Script_Generator algorithm
At this time, the screen should look like the following:
...
At this point, the script will be downloaded to your computer’s hard disk, and you will see the message at the bottom left of your browser window be replaced by just the name of the downloaded file:
Run the script returned by the EF_Rsync_Script_Generator algorithm
Windows users please note: Before proceeding, Windows users will need to complete additional steps to prepare their machine to work with rsync. Please follow the directions here.
...
The workset in our example only contained one volume, Buch der Lieder by Heinrich Heine with the HathiTrust volumeID mdp.39015012864743. The corresponding file is called mdp.39015012864743.json.bz2.
(Optional) Uncompress the downloaded files
Because the feature data files are compressed, you may need to uncompress them into JSON-formatted text files, depending on your need. The compression used is bzip2. If you are using the files with the HTRC Feature Reader, the library will deal with the compression automatically.